(TimeStory 3 is in progress, and will contain some significant updates to the app. I’ve decided to write about major milestones and interesting programming challenges along the way.)
The first major feature change in TimeStory 3 is a rework of its CSV import/export features. This has been long in coming; CSV import arrived in version 1.1, and export in 1.2, and they’ve remained mostly untouched since then other than bug fixes and small incremental improvements. 3.0 will contain a big change; here are some of the interesting parts.
Much greater configurability
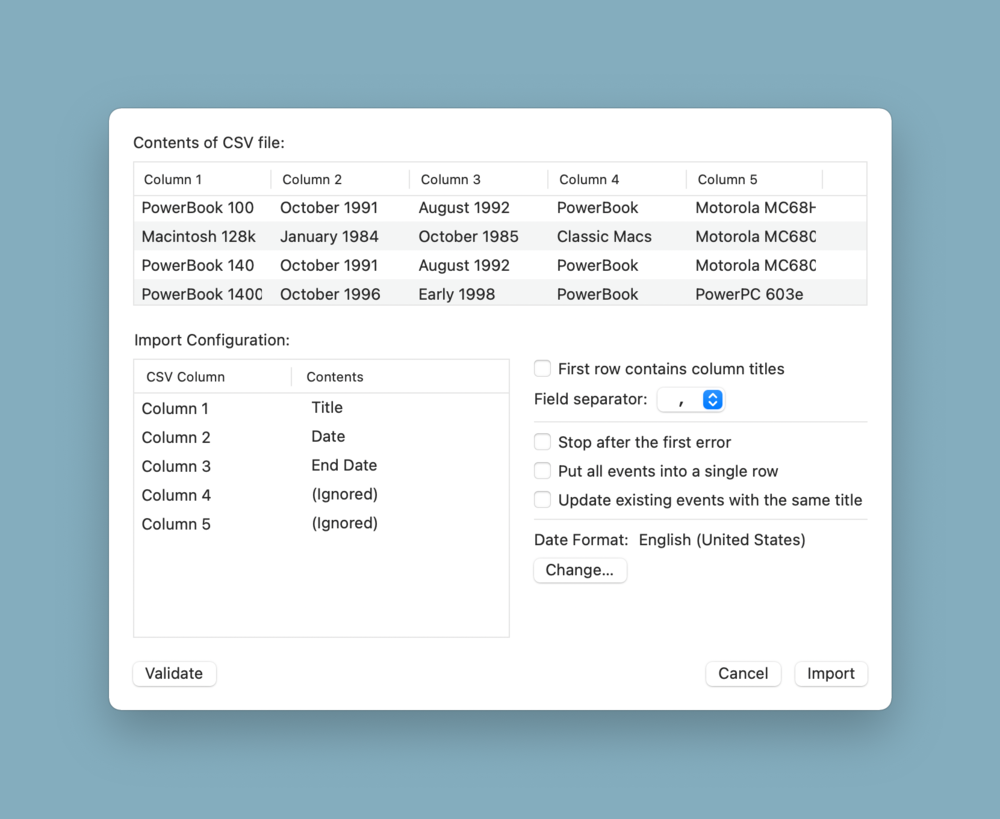
The original CSV importer only let you assign four columns: event title, start date, end date, and section. The CSV exporter always used a fixed format; there was no configurability at all! This has all changed.
- Both dialogs now let you freely select the columns to extract from input or write into output, along with other format options, using a similar UI.
- The set of supported columns is now much larger, including style information like Graphic Color and formerly-missing properties like Tags.
- Some columns now have new variants; for example, End Date can now be specified as inclusive or exclusive, and Section Name can be specified to just be the immediately enclosing section or all enclosing sections (when you use subsections in your document).
Internally, the code was restructured to ensure that import and export stay symmetric in the future, and to make it easier to keep the available CSV columns up to date. Per-column-type code was pulled out into a set of simple implementations of common “column” protocols, and the import and export jobs are now totally generic over the set of columns chosen.

(Click for full-size images)
(May change before release)
Format detection on import
The importer will now also try to automatically detect the format, including separator, header row presence, and basic column layout.
This was interesting to work on. First, the code scans the first few lines with different field separators, figuring out which one yields the most columns. It then re-scans from the beginning, looking for formatted dates, comparing dates to distinguish start from end, and so on. It actually uses a simple “voting” system; after ten rows, for example, there may have been a couple of plausible start dates in Column 1, but seven or eight candidates in Column 2. Column 2 would be chosen, under the assumption that Column 1 is just a title or description field which happened to contain a valid date. This seems to work pretty well.
(And as a special case, if the first row contains only column titles which are character-for-character exact matches with TimeStory CSV export fields, the whole thing short-circuits with a perfect match. So export/import round trips now work without any manual configuration.)
Annoyance: dealing with Excel dates
In Excel (on a US English setup), if you just type a date into a field, and that date is in the current year, it formats that date as DD-MMM by default; for example, 24-Jun. This wasn’t parsed by the old CSV importer. For people using Excel as an informal, quick way of entering CSV data, this created unnecessary friction. I put in a special-case parser for this date format (or for the corresponding localized format in other languages, of course).
Using Combine
Also, with TimeStory 3, I’m tentatively planning on dropping support for macOS Mojave. This opens the door to some APIs and technologies that Apple only makes available on newer platforms. Notably, I found Combine a great fit for the asynchronous import/export tasks; they now each offer a status publisher on which they post row-by-row progress updates from their background work queue. Combine lets me trivially throttle and consolidate those updates, while safely delivering them to the main thread, with what I find to be very explicit, clear code, replacing equivalent code where I’d done my own throttling and queue-hopping. This is three-year-old news, I know, but I like Combine quite a bit.